MariaDBのバックアップ方法はいくつかありますが、今回ご紹介する方法は、ダンプファイルの作成という方法になります。MariaDBのダンプファイルの作成は、通常、CUI(黒い文字だけの画面)でmysqldumpというコマンドラインツールを用いて行います。MariaDBをWindowsにインストールすると、C:\Program Files\MariaDB 10.2\binディレクトリに、mysqldump.exeという実行ファイルが配置されます。これがコマンドラインツールです。
ここでは、CUIでmysqldumpを実行するのではなく、HeidiSQLというGUIツールを用いてダンプファイルのバックアップおよびリストアする方法をご紹介します。
準備
説明用のデータベースの作成から始めます。
スタートメニューから「MySQL Client (MariaDB 10.2(x64))」をクリックします。
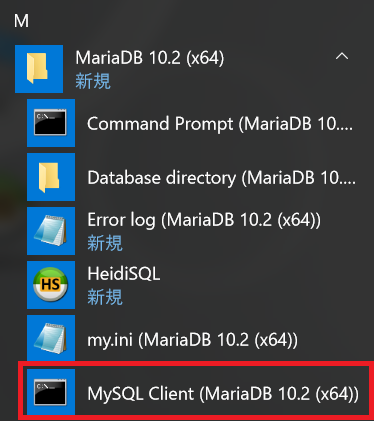
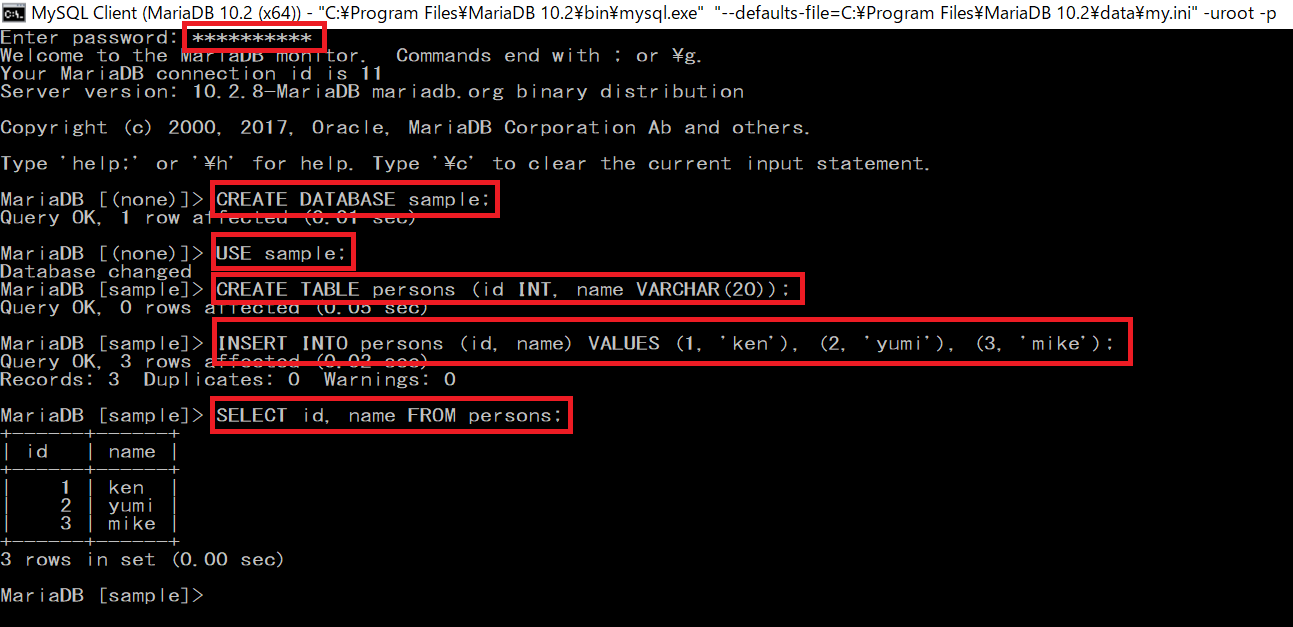
表示された画面にrootユーザーのパスワードを入力を入力し、データベースおよびそのテーブルを作成します。以下は、コマンドの説明です。「–」で始まる行はコメントを表しておりますので、実際には入力する必要はありません。
-- sampleデータベースを作成します
CREATE DATABASE sample;
(out)
-- sampleデータベースの使用を宣言します
USE sample;
(out)
-- personsテーブルを作成します
CREATE TABLE persons (id INT, name VARCHAR(20));
(out)
-- personsテーブルにデータを挿入します
INSERT INTO persons (id, name) VALUES (1, 'ken'), (2, 'yumi'), (3, 'mike');
(out)
-- personsテーブルのデータを確認します
SELECT id, name FROM persons;
HeidiSQLでバックアップ
まず最初に、HeidiSQLを立ち上げます。
今回は、rootユーザーで接続します。そのため、rootユーザーのパスワードを入力した後、「開く」をクリックします。
左側にデータベースの一覧が表示されていることが確認できます。
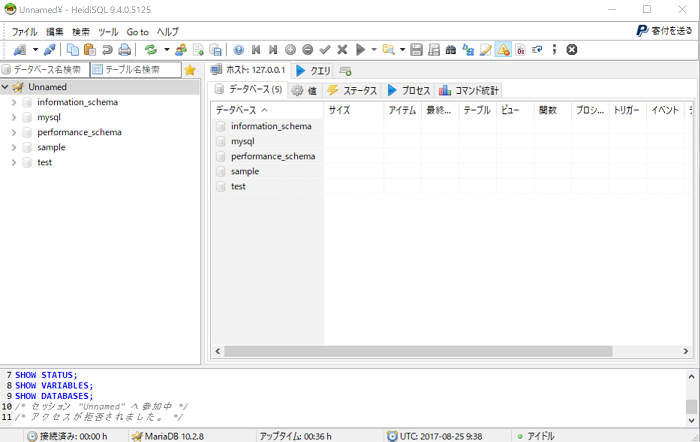
今回は、sampleデータベースをバックアップしようと思います。
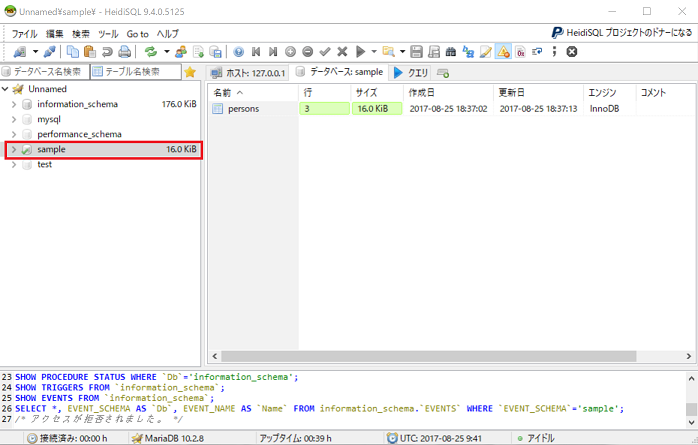
メニューバーのツールから「データベースをSQLとしてエクスポート」をクリックします。
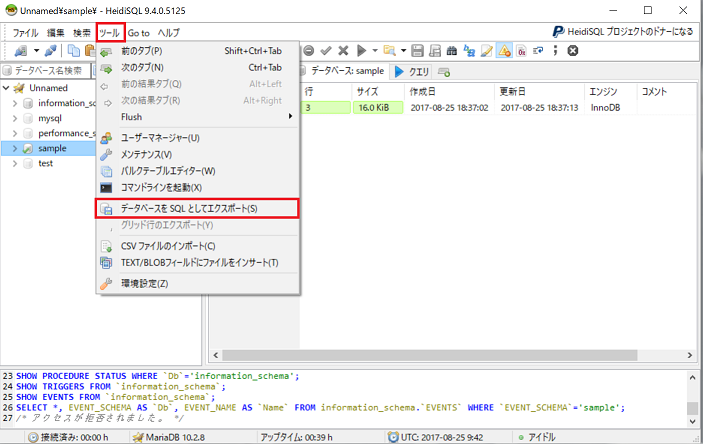
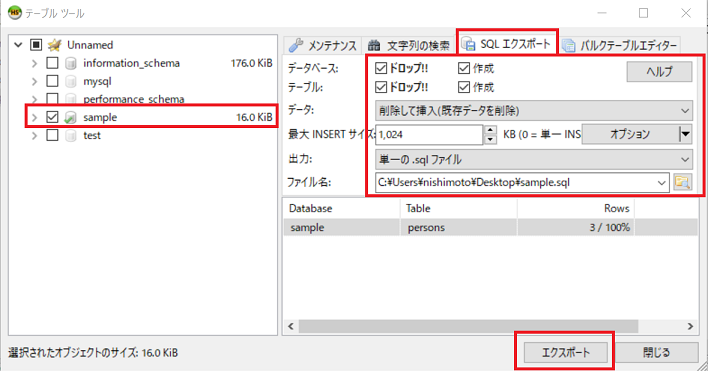
左側の領域で、sampleデータベースにチェックを入れます。右側の領域で、「SQLエクスポート」タブをクリックし、どのようにしてバックアップファイルを作成するかを指定します。リストアするときに、どのようにしてリストアするのかを指定するのではなく、事前に、どのようにしてリストアをするのかをバックアップファイルに記載するということにご注意ください。指定した内容は次になります。
- データベース:すでに同一のデータベースが存在していた場合は、削除して新たに作成します
- テーブル:すでに同一のテーブルが存在していた場合は、削除して新たに作成します
- データ:既存データを削除して、新たにデータを挿入します
- 最大INSERTサイズ:データ挿入時のコマンドの長さを指定します
- 出力:単一の.sqlファイルとして出力します
- ファイル名:バックアップファイルのファイルパス
条件を確認して、問題が無ければ「エクスポート」をクリックして、バックアップファイルを作成します。ちなみに、HeidiSQLを管理者権限で実行していない場合は、異なるディレクトリへエクスポートできないことにご注意ください。その場合は、デスクトップなどにエクスポートしてください。
エクスポートされた.sqlファイルをメモ帳で開くと、次のようになっております。
-- --------------------------------------------------------
-- ホスト: 127.0.0.1
-- サーバーのバージョン: 10.2.8-MariaDB - mariadb.org binary distribution
-- サーバー OS: Win64
-- HeidiSQL バージョン: 9.4.0.5125
-- --------------------------------------------------------
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET NAMES utf8 */;
/*!50503 SET NAMES utf8mb4 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
-- sample のデータベース構造をダンプしています
DROP DATABASE IF EXISTS `sample`;
CREATE DATABASE IF NOT EXISTS `sample` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `sample`;
-- テーブル sample.persons の構造をダンプしています
DROP TABLE IF EXISTS `persons`;
CREATE TABLE IF NOT EXISTS `persons` (
`id` int(11) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- テーブル sample.persons: ~3 rows (approximately) のデータをダンプしています
DELETE FROM `persons`;
/*!40000 ALTER TABLE `persons` DISABLE KEYS */;
INSERT INTO `persons` (`id`, `name`) VALUES
(1, 'ken'),
(2, 'yumi'),
(3, 'mike');
/*!40000 ALTER TABLE `persons` ENABLE KEYS */;
/*!40101 SET SQL_MODE=IFNULL(@OLD_SQL_MODE, '') */;
/*!40014 SET FOREIGN_KEY_CHECKS=IF(@OLD_FOREIGN_KEY_CHECKS IS NULL, 1, @OLD_FOREIGN_KEY_CHECKS) */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
HeidiSQLでリストア
エンコードを指定せずにリストア
HeidiSQLでエンコードを指定せずにリストアするには、メニュバーのファイルから「SQLファイルを実行」をクリックします。ファイルを選択する画面が表示されますので、.sqlファイルを指定します。ここでは、先ほどエクスポートしたファイルを指定します。
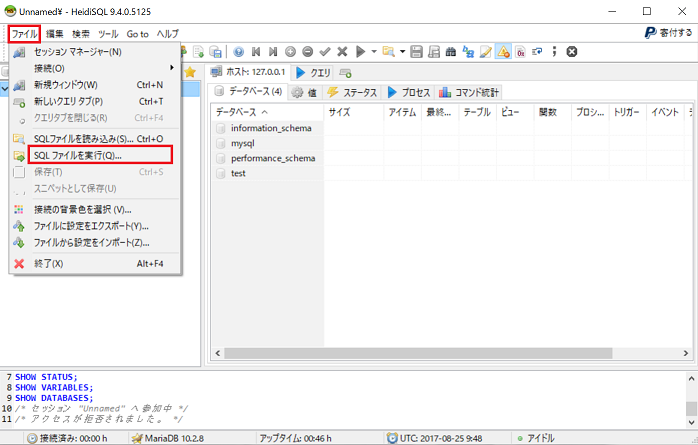
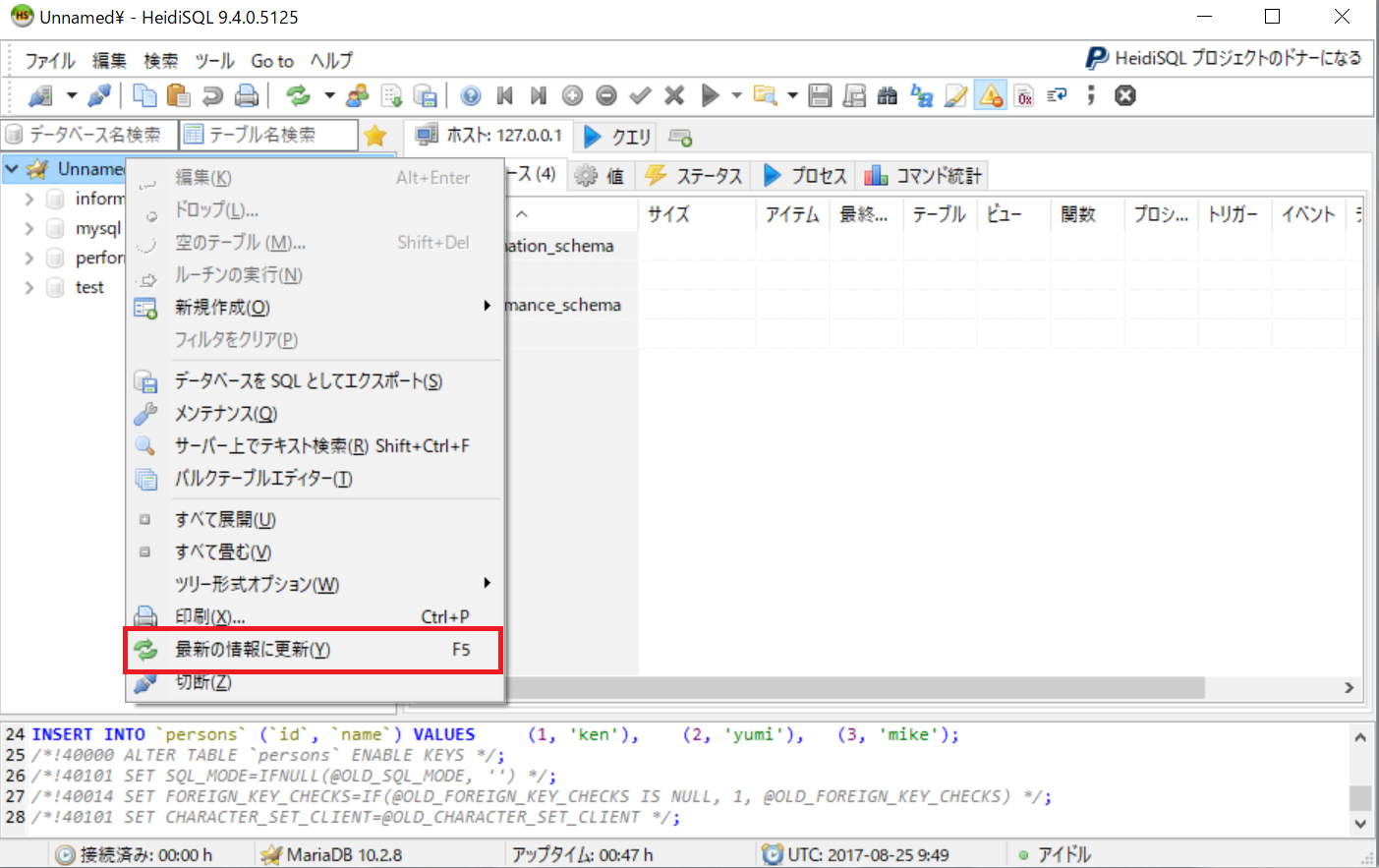
左側の領域を最新の情報に更新するために、左側の領域のツリーのトップで、右クリックからコンテキストメニューを表示させ、「最新の情報に更新」をクリックします。
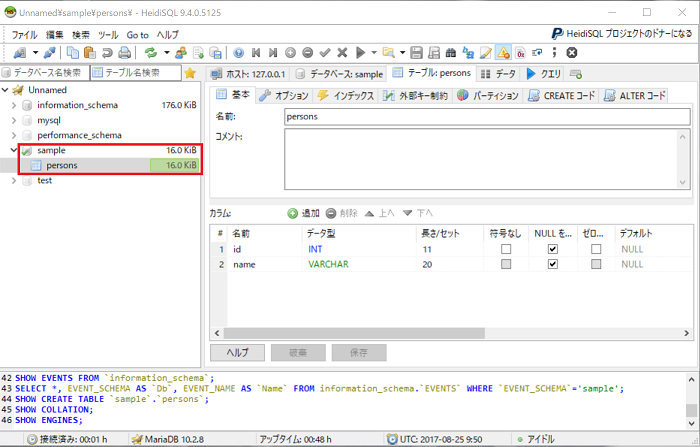
sampleデータベースがリストアされていることが確認できます。
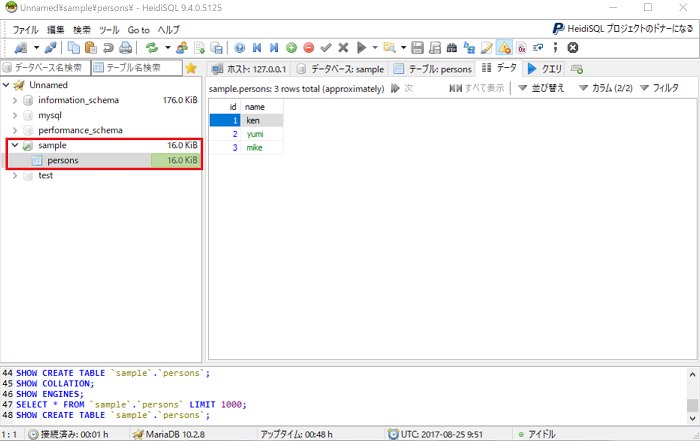
エンコードを指定してリストア
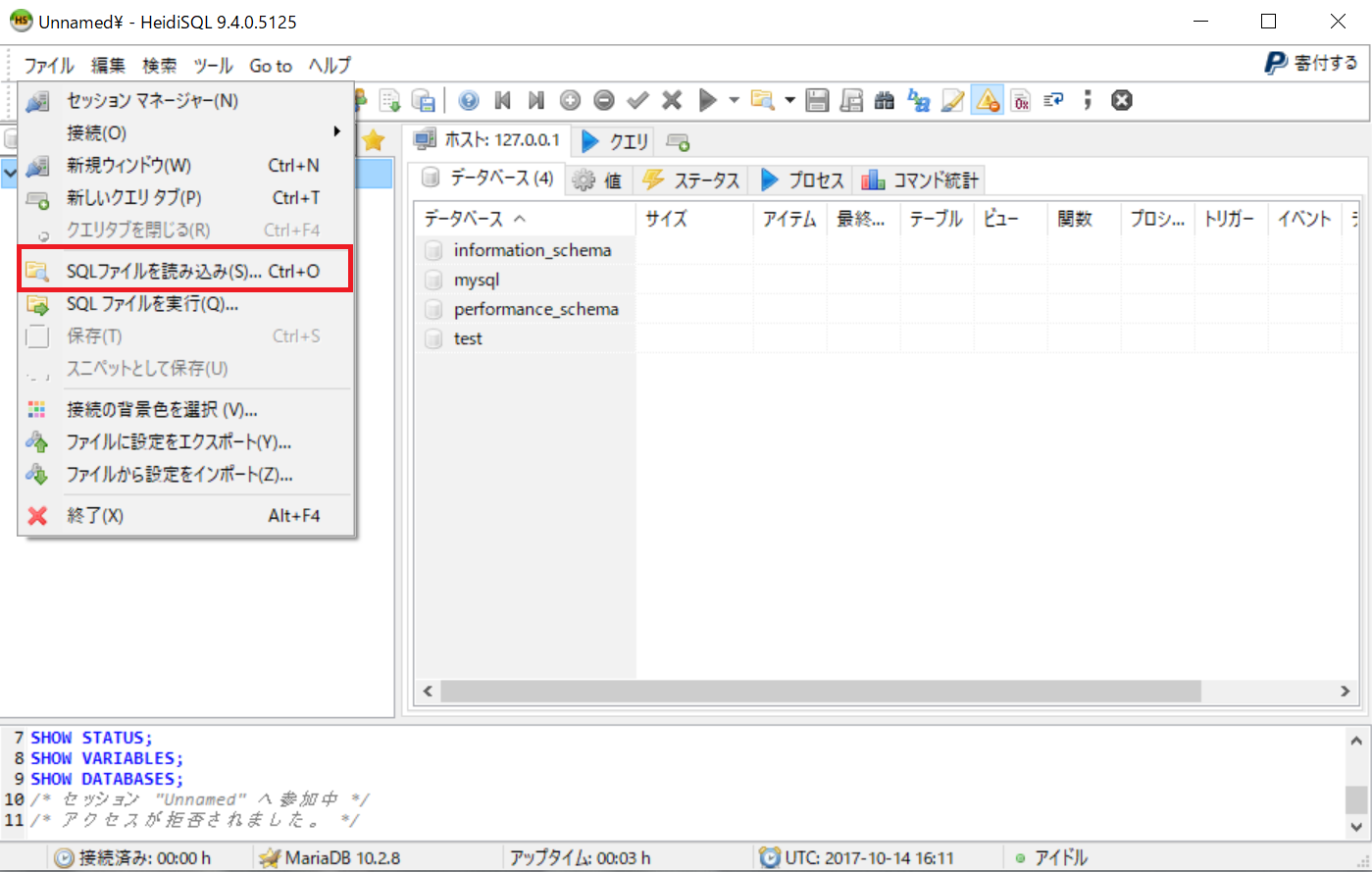
HeidiSQLでエンコードを指定してリストアするには、メニュバーのファイルから「SQLファイルを読み込み」をクリックします。
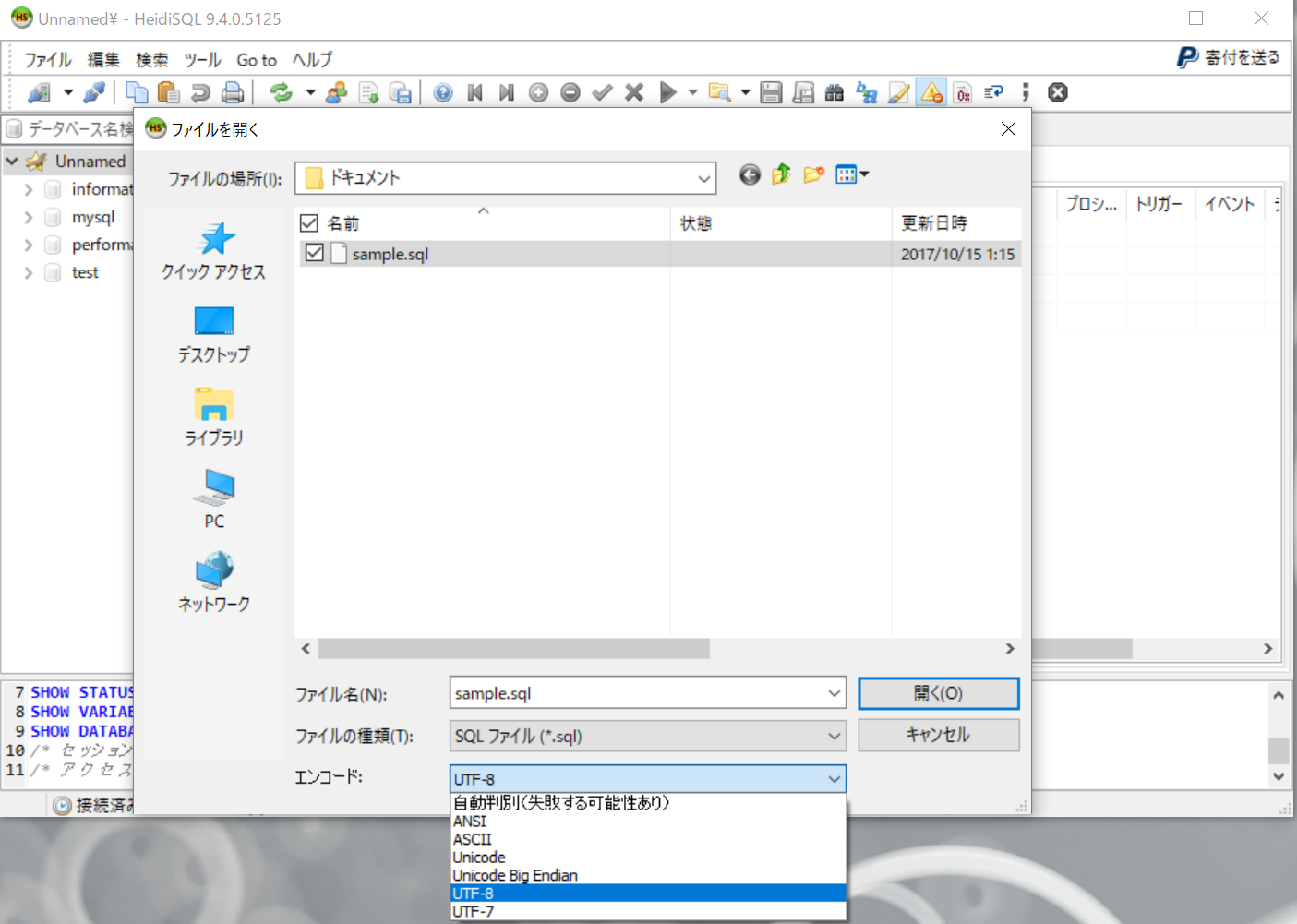
ファイルを選択する画面が表示されますので、.sqlファイルを指定します。ここでは、先ほどエクスポートしたファイルを指定します。また、エンコードの指定が行えますので、適切なエンコードを指定します。
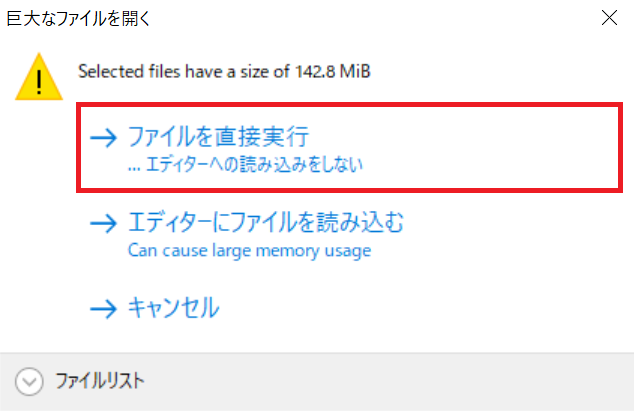
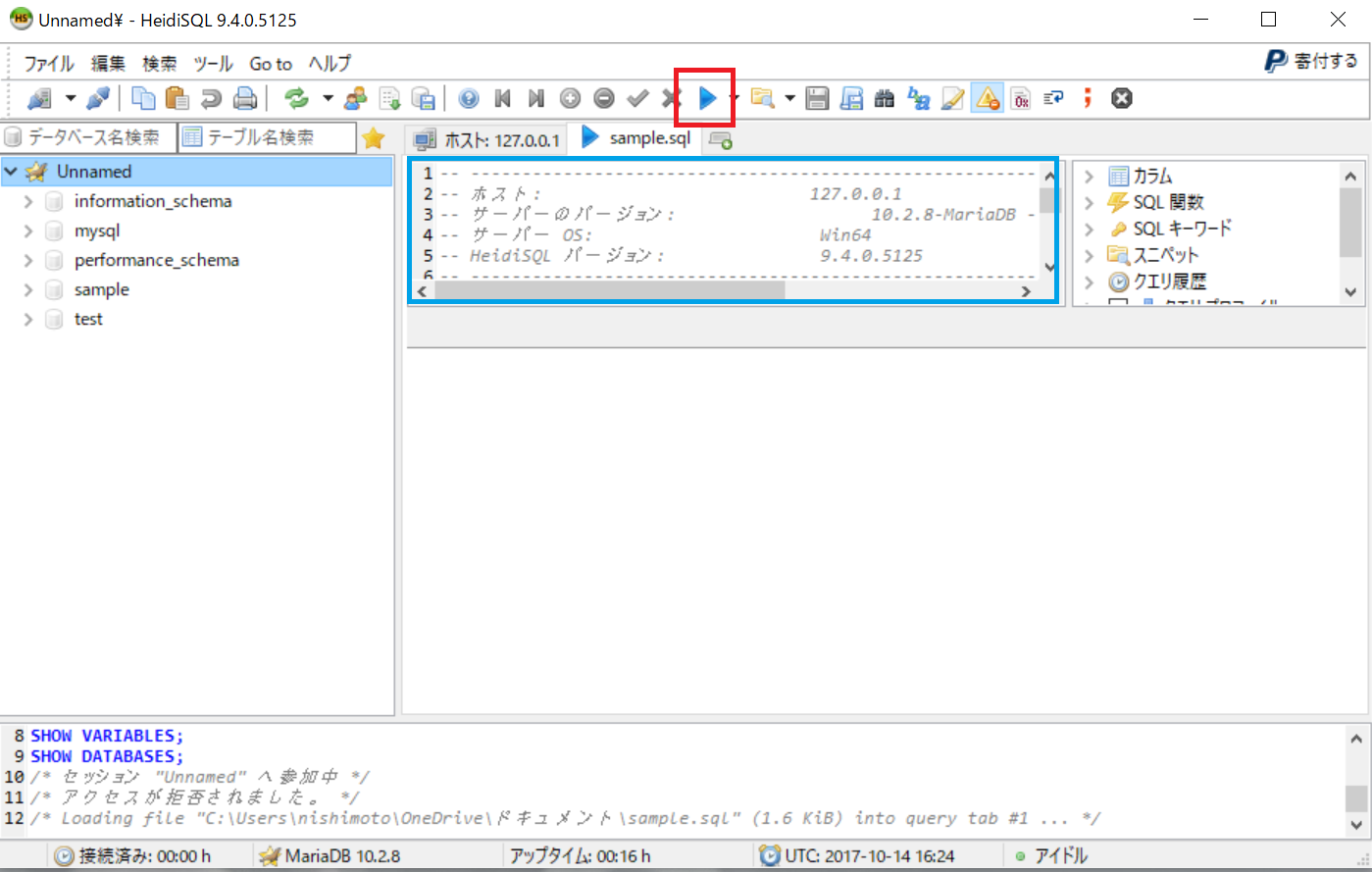
ファイルの容量が小さい場合には、下図の青枠で囲まれた部分に読み込まれますので、赤枠で囲ったボタンをクリックすると、ファイルが取り込まれます。
ファイルの容量が大きい場合には、下図のような案内が表示されますので、特別な事業がない限りは「ファイルを直接実行」をクリックすると、ファイルが取り込まれます。