ここでは、ページビュー数から年齢とページの関係性を視覚的に確認し、年齢別にユーザーがどのコンテンツに興味を抱くか、その傾向を探っていく。この傾向がユーザー像を捉える一つのヒントとなる。傾向が分かると、それに合わせたコンテンツを用意すればページビュー数を増加させるために必要なコンテンツはどのようなものかを理解できるだろう。
必要なデータはGoogleアナリティクス(ユニバーサルアナリティクス)から抽出する。
また、分析の手順は、Googleアナリティクスから抽出したデータを少し加工して、Rを用いてクロス集計表を作成し、コレスポンデンス分析を行う。
Googleアナリティクスからデータを抽出する方法を見ていく前に、Googleアナリティクスにおけるユーザーの年齢と性別について、簡単にご説明しておく。
Googleアナリティクスにおけるユーザーの年齢と性別
どのようにしてGoogleがユーザーの年齢と性別を決定しているのかというと、基本的には「Cookie」と「アクセス履歴」を元に予測して決めている。このほか、ソーシャルネットワークサイトなどや、Googleプロフィール由来の情報も利用される。詳しくは、「特定のユーザー層に広告を表示する – AdWords ヘルプ」を参照して欲しい。
つまり、Googleアナリティクスにおけるユーザーの年齢と性別は必ずしも正確とは限らない。
また、サイトに訪問したユーザーの全てに年齢と性別を割り当てられてるとは限らない。
あなたがGoogleにどのように年齢と性別を予測されているのかを知りたいならば、「Googleの広告設定」を訪れてみて欲しい。
データ抽出
それでは、Googleアナリティクスからデータの抽出を行う手順を見ていく。
Googleアナリティクスを開き、データを抽出したいビューを選択する。その後、「カスタム」タブの「新しいカスタムレポート」をクリックする。
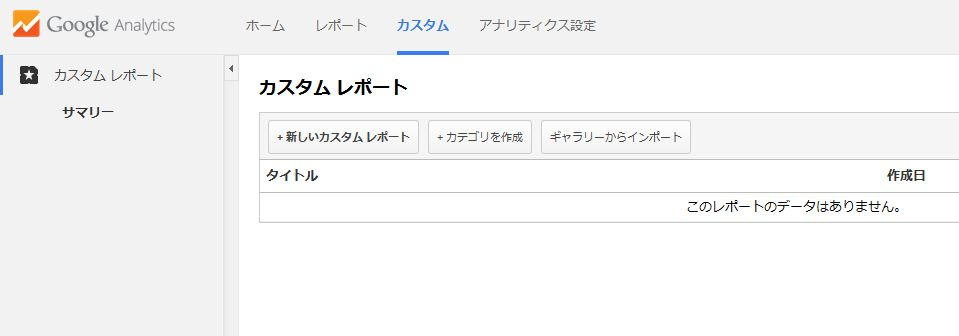
次に、ディメンションに「ページ」と「年齢」、指標に「ページビュー数」を追加し、最後に、「保存」をクリックする。
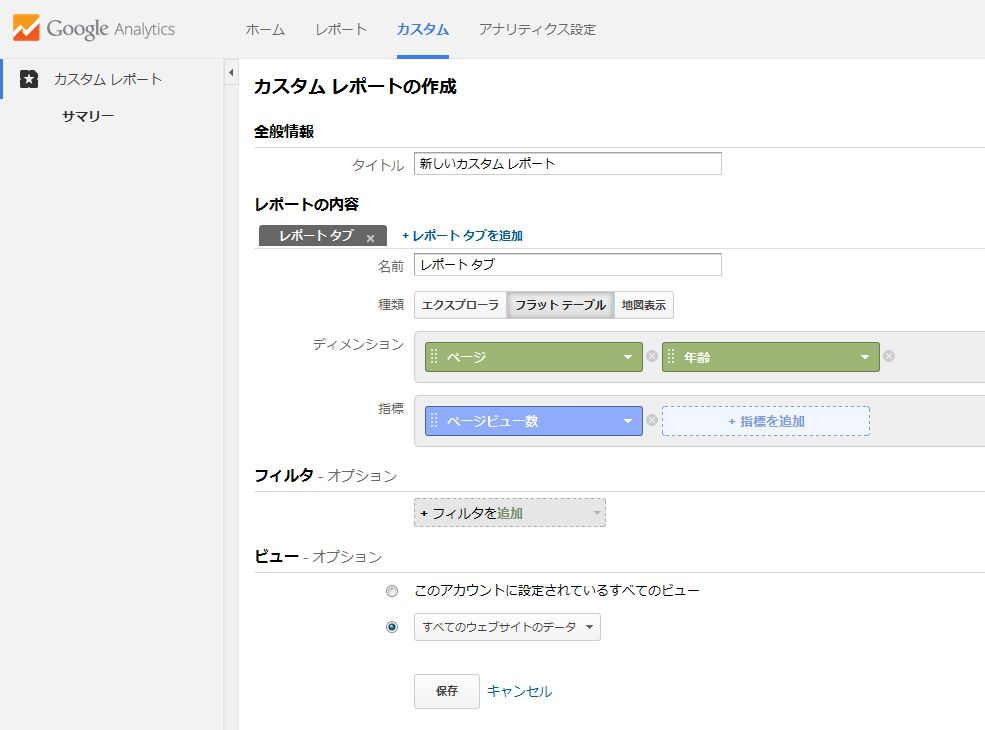
下の画面が表示されたら、右上のところのでデータを抽出する期間を設定した後、「エクスポート」クリックして、適当な保存形式で保存する。これで、データの抽出は完了だ。
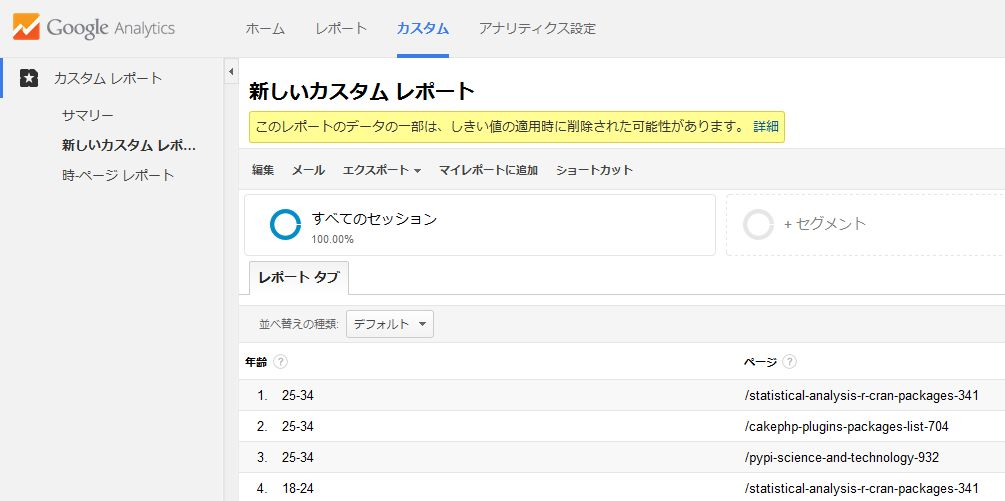
Rによるコレスポンデンス分析
抽出したデータはそのままでは、Rに読み込めないため、加工してCSV形式として再度保存しておく。
ここではサンプルデータとして、当サイトの2014年9月1日~30日までの「CRAN Task View」に関するサイトを対象としたデータを用いる。ページ(URL)はそのままでは長く見づらいので、4文字に加工してある。
年齢,ページ,ページビュー数
25-34,baye,39
18-24,baye,19
35-44,baye,17
25-34,clus,34
18-24,clus,17
25-34,grap,23
25-34,hand,10
25-34,high,31
35-44,high,22
25-34,mach,39
35-44,mach,26
18-24,mach,23
25-34,mult,18
25-34,opti,15
35-44,opti,12
35-44,psyc,18
25-34,r-cr,27
25-34,surv,22
18-24,time,62
25-34,time,44
35-44,time,24
コレスポンデンス分析を行うために、MASSパッケージをインストールしておく。
> install.packages("MASS")
それでは、実際にコレスポンデンス分析を行う。
> library(MASS)
> df <- read.csv("sample.csv", header = TRUE)
> x <- xtabs(ページビュー数 ~ ページ + 年齢, data = df)
> print(x)
年齢
ページ 18-24 25-34 35-44
baye 19 39 17
clus 17 34 0
grap 0 23 0
hand 0 10 0
high 0 31 22
mach 23 39 26
mult 0 18 0
opti 0 15 12
psyc 0 0 18
r-cr 0 27 0
surv 0 22 0
time 62 44 24
> corr <- corresp(x, nf = 2)
> print(corr)
First canonical correlation(s): 0.5067508 0.4453843
ページ scores:
[,1] [,2]
baye -0.1133867 0.13218927
clus 0.7604587 0.86038856
grap 1.6397076 -0.72500710
hand 1.6397076 -0.72500710
high -0.3470042 -1.36175755
mach -0.4637990 0.06486299
mult 1.6397076 -0.72500710
opti -0.4874788 -1.40678031
psyc -3.1464619 -2.25899682
r-cr 1.6397076 -0.72500710
surv 1.6397076 -0.72500710
time -0.5018952 1.26013012
年齢 scores:
[,1] [,2]
18-24 -0.5057571 1.7954243
25-34 0.8309231 -0.3229068
35-44 -1.5944720 -1.0061218
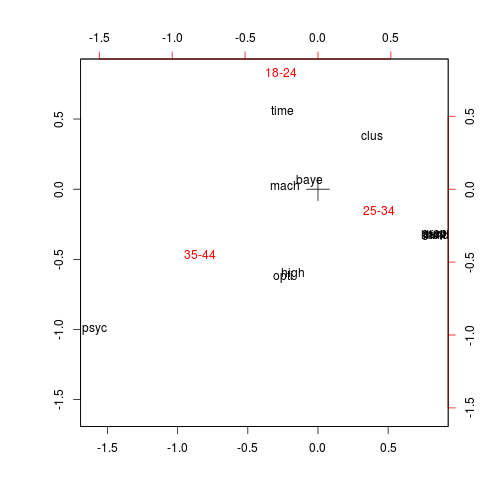
> biplot(corr)
ついでに、階層的クラスター分析も行っておく。
> dis <- dist(corr$score)
> clu <- hclust(dis)
> plot(clu, hang = -1)
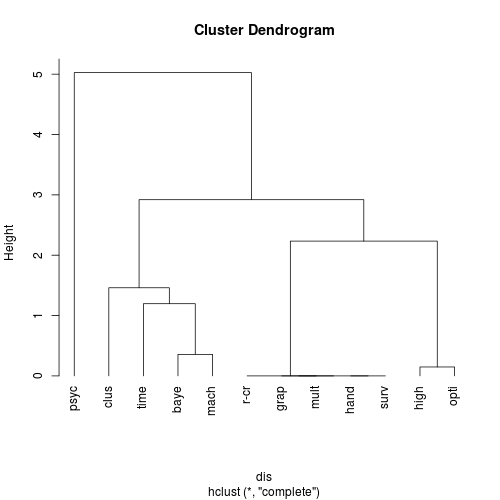
グラフを読む
グラフから読み取れることを以下に挙げる。
また、階層的クラスター分析のグラフからHeightが1以下としてみると、5つのクラスターに分類されていることが分かる。
- mach(機械学習&統計学習)とbaye(ベイズ推論)は年齢18-44で均等に訪問されている。
- time(時系列解析)は年齢25-44に比べて年齢18-24によく訪問されている。
- clus(クラスター分析&有限混合モデル)は年齢35-44に比べて年齢18-34によく訪問されている。
- high(Rでの高性能並列コンピューティング)とopti(最適化と数理計画)は年齢18-24に比べて年齢25-44によく訪問されている。
- psyc(心理モデルや手法)は年齢18-34に比べて年齢35-44によく訪問されている。
- r-cf(CRAN Task Views)、grap(Rグラフィカルモデル)、mult(多変量統計)、hand(時空間データの処理と分析)、surv(生存時間解析)は年齢18-24および年齢35-44に比べて年齢25-34によく訪問されている。
以上のことから、様々な年齢の方に見ていただくためには、機械学習や統計学習、ベイズ推論などの記事を書いて、CRAN Task Viewに関係する記事にきちんと導線を張っておくことであると予測される。
また、年齢18-24の読者を増やしたいと考えた場合は、時系列解析の記事を書けばよいことも予測される。
まとめ
ユーザー像を具体的に思い描くために、当サイトの一部ページを用いて、Googleアナリティクスからページビュー数、年齢、ページのデータを使って見てきた。そして、どのように対応すればページビュー数を増やせるかのヒントを得た。
また、当サイトのサンプルデータでは示せなかったが、ターゲットのユーザー像とのミスマッチを測るのにも使える。
例えば、アパレル関係のECサイトの場合、シャツ関連のページを訪問しているユーザーの大部分が年齢25-34だが、画像のモデルの年齢が18-24の場合、ミスマッチとみなせる。この場合は、商品にもよるがモデルを変えたり、ターゲットが年齢25-34の商品に導線を張るなどの対策が考えられる。
Googleアナリティクスを触ってみれば分かると思うが、実に様々な指標、ディメンションが用意されている。
目的に合わせて指標、ディメンションを選んでコレスポンデンス分析を行うと、きっと新たな発見があるので、是非一度分析してみてはどうだろうか。