
新規の機能性素材やサプリメントの有効性を評価するようなヒト試験(介入試験)は、製品価値を客観的に証明するための極めて重要なプロセスです。
しかし、試験データの解析において以下のような課題に直面することは少なくありません。
- 「試験によって得られた膨大なデータから、どのように有益な知見を抽出すべきか判断が難しい」
- 「主要な評価項目で有意差が確認できなかった際、どのような追加解析が科学的に許容されるのか曖昧である」
- 「得られた解析結果を製品の機能性表示や論文発表に用いるにあたり、統計的な妥当性が十分に担保されているか確信が持てない」
これらの課題を解決し、科学的エビデンスとしての信頼性を維持するためには、データ解析における2つの異なるアプローチである「探索的データ分析」と「仮説検証型データ分析」の本質的な違いを理解し、厳格に区別して運用する必要があります。
本記事では、サプリメントの介入試験を具体的なユースケースとして挙げながら、これら2つのデータ分析アプローチの定義、役割の相違、および実務において両者を混同した際に生じる科学的・商業的リスク、さらには具体的な実務への落とし込み方について詳細に解説します。
探索的データ分析の定義と役割
探索的データ分析とは、データが持つ構造や分布、変数間の関連性を多角的に観察し、「新たな仮説の構築(仮説生成)」やインサイトの抽出を行うアプローチです。
目的とアプローチの特徴
探索的データ分析の目的は、データの背後にある隠れたパターンや新たな知見を見出すことにあります。分析を開始する段階においては、必ずしも事前に厳密な仮説を構築しておく必要はありません。データ自体に「何を語らせるか」を主眼に置き、以下の手法を用いて柔軟にデータを探索します。
- 基礎的なアプローチ:
- データの可視化: 箱ひげ図、散布図、ヒストグラム等を用いたデータの分布や外れ値の視覚的確認。
- 要約統計量の算出: 平均値、中央値、標準偏差などの基本統計量による全体の傾向把握。
- 多角的なクロス集計: 被験者の属性(性別、年齢層など)や生活習慣等の共変量を用いたセグメント解析。
- 発展的なアプローチ:
- クラスター分析: 被験者やデータの類似性に基づいて自動的にグループ分け(クラスタリング)を行い、潜在的なサブグループ(例:サプリメントの効果が出やすい高反応性群と出にくい低反応性群)を分類・同定する。
- ネットワーク分析: 多くの変数(バイオマーカー、臨床指標、生活習慣項目など)の相互作用や相関関係をネットワーク図(グラフ構造)として可視化し、データ全体の構造や関係性のハブとなる中心的な因子を特定する。
- 次元削減・主成分分析: 測定された多数の評価項目の情報を合成変数(主成分)に圧縮し、被験者ごとのデータ全体のばらつきや分布の偏りを低次元のグラフ上で直感的に把握する。
サプリメント介入試験における具体例
新規に開発した「整腸作用を持つ乳酸菌サプリメント」の介入試験データを例に説明します。
当初想定していた「被験者全体における排便回数の増加」という全体解析では、群間に統計学的な有意差が認められなかったと仮定します。この段階で解析を終了するのではなく、データの背景にある要因を探るために探索的データ分析を実施します。
被験者の背景データ(年齢、性別、運動習慣など)を掛け合わせて可視化したところ、以下の傾向が観察されました。
「被験者全体では差が見られないものの、『20代女性』かつ『日常的に運動習慣がある』という特定のセグメントにおいて、サプリメント摂取後に排便回数が増加している顕著な分布の偏り(偏位)が確認された」
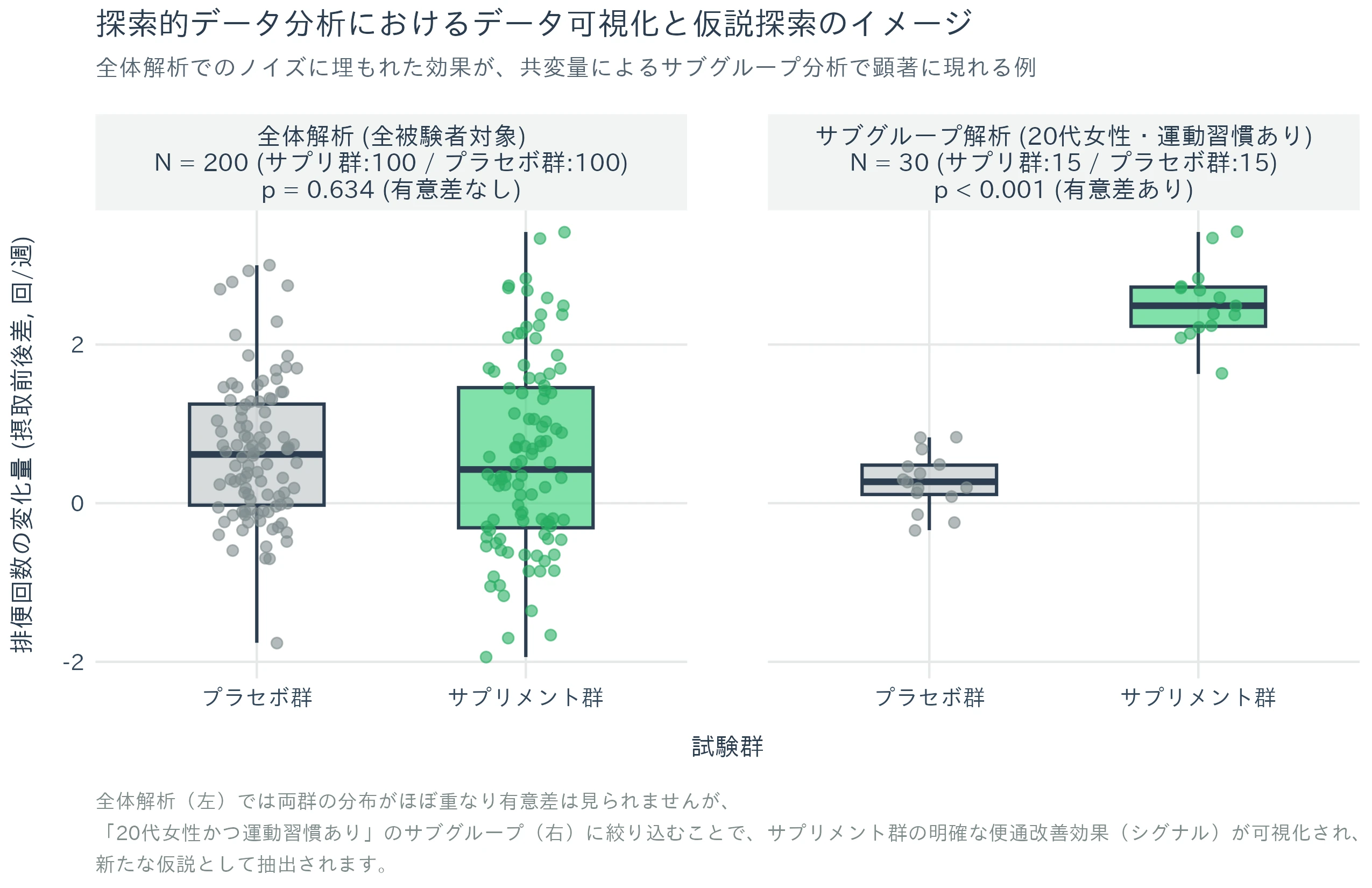
このように、データ分析の初期段階や事後解析において、「特定のターゲットや条件下において効果が発現する可能性があるのではないか」という新たな作業仮説を導き出すプロセスが探索的データ分析に該当します。
イノベーションの源泉としての探索的データ分析
p値による「白黒の判定」を重視する検証的アプローチとは異なり、探索的データ分析は新たな付加価値やイノベーションを創出するための「仮説生成器」としての役割を持ちます。当初の設計にはなかった「想定外のターゲット層での効果」や「予期せぬ副次的メリット」を発見することは、新規プロジェクトの立ち上げや製品のポジショニング戦略の見直しに直結する極めて生産的な活動です。探索的データ分析は妥協の産物ではなく、科学的発見のプロセスにおいて不可欠な起点です。
仮説検証型データ分析の定義と役割
仮説検証型データ分析は、試験開始前に策定された特定の仮説が、統計学的に妥当であるかを科学的に検証し、「仮説の真偽を実証する(仮説検証)」アプローチです。
目的とアプローチの特徴
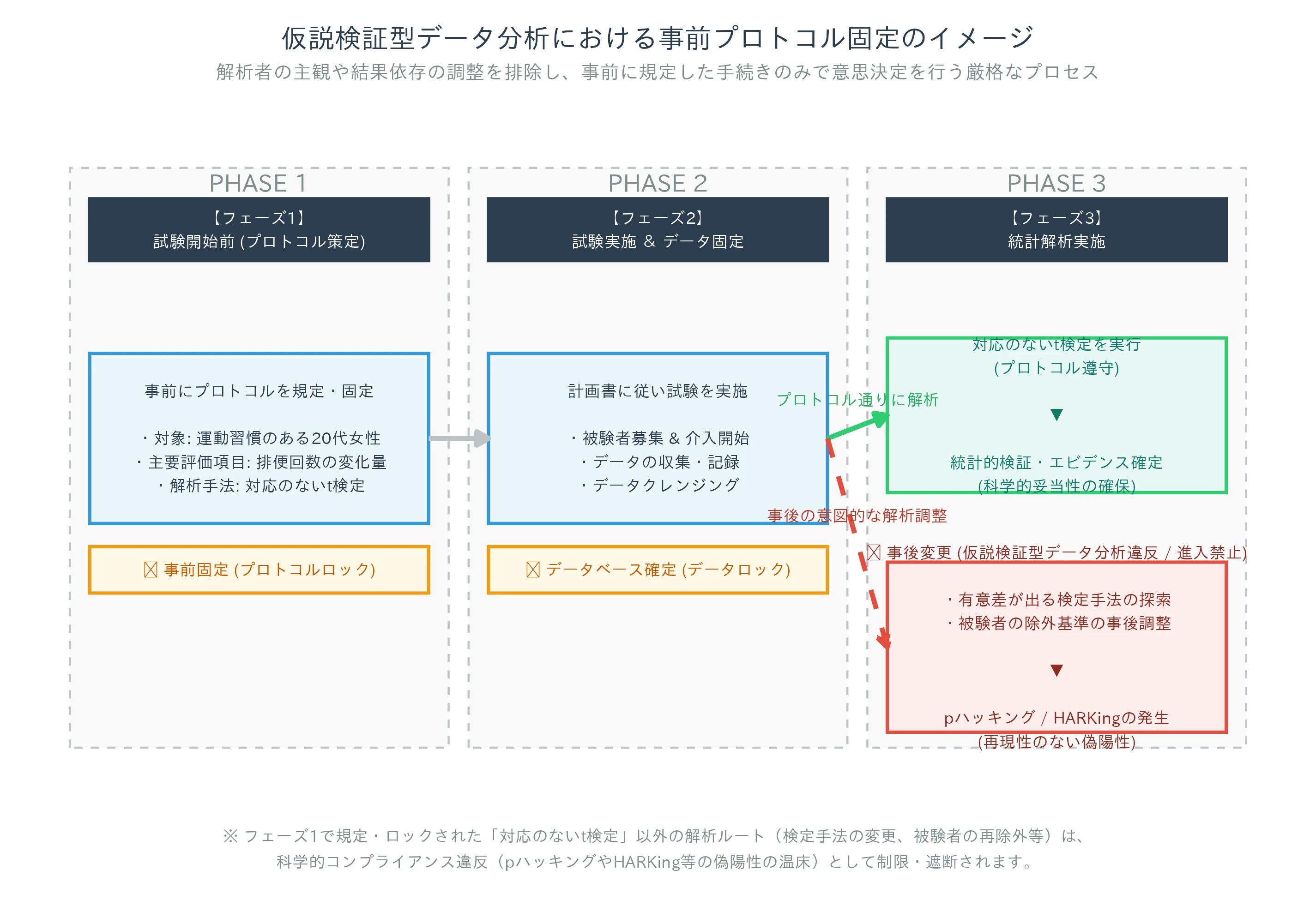
仮説検証型データ分析の目的は、事前に計画された特定の仮説(例:「本サプリメントの摂取は、対照群と比較して排便回数を統計学的に有意に増加させる」など)を立証することです。そのため、解析のプロセスには極めて厳格なルールが課されます。
- プロトコル(試験実施計画書)の事前策定: 試験開始前に、主要評価項目(プライマリエンドポイント)、副次評価項目、対象者の選択・除外基準、および統計解析計画(使用する統計テストや有意水準)を全て規定します。
- ルールの遵守: 試験実施後、事前に規定した解析計画書に沿って一意に統計解析を実行します。結果の良し悪しによって、途中で解析手法や評価項目を変更することは認められません。
- 意思決定の実行: 算出されたp値(有意確率)が、事前に設定した有意水準(一般に α = 0.05) を下回るか否かによって、仮説の採択を厳格に決定します。
サプリメント介入試験における具体例
前述の乳酸菌サプリメントの試験において、探索的データ分析によって「運動習慣のある20代女性に効果がある」という仮説が構築されました。しかし、これはあくまで「仮説」であり、現時点では統計的な偶然による偽陽性(たまたまそのようなデータが得られただけ)の可能性を排除できません。
この仮説をエビデンスとして確立するためには、仮説検証型データ分析のアプローチに基づき、新たな検証試験を設計・実施する必要があります。
- プロトコルの策定
- 対象被験者を「運動習慣を有する20代女性」に限定する。
- 被験者を「乳酸菌サプリメント摂取群」と「対照群(プラセボ)」にランダム化し、二重盲検比較試験とする。
- 主要評価項目を「摂取4週間後における排便回数」と定め、解析手法は「対応のないt検定」を用いると事前に規定する。
- 試験の実施と解析計画の遵守
- 試験終了後、あらかじめ規定した統計解析計画書通りに「対応のないt検定」を実施する。
- 統計的検証
- 算出されたp値が 0.05 未満であれば、「乳酸菌サプリメントは運動習慣を有する20代女性の便通を有意に改善する」という仮説が検証された(エビデンスとして立証された)と結論付けます。
実務への落とし込み:臨床試験登録と「社内プロトコル管理」の推奨
仮説検証型データ分析における最大の要諦は、解析手順を「事後変更」させないことです。
医療・バイオ分野のアカデミア領域では、試験開始前に計画を公的データベース(国内では UMIN-CTR、国際的には ClinicalTrials.gov など)に事前登録することが国際的なルール(国際医学雑誌編集者会議:ICMJEによる勧告)となっています。これにより、事後のデータつまみ食いや未公表(出版バイアス)を防止しています。
民間企業の研究開発においても、公的な試験登録データベースへの登録を行うことが強く推奨されますが、それに加えて実務的な運用として「社内プロトコル登録」を導入することをお勧めします。
具体的には、試験開始前(あるいはデータキーイン前)に「統計解析計画書」を作成し、社内の共有ストレージやバージョン管理システム上でタイムスタンプを付与した状態で固定・保管します。これにより、事後に解析方法を都合の良いように変えていないことを客観的に証明でき、データの科学的健全性とコンプライアンスレベルを大幅に向上させることが可能となります。
探索的データ分析と仮説検証型データ分析の対比
これら2つのアプローチの相違点について、以下の比較表に整理します。
| 比較項目 | 探索的データ分析 | 仮説検証型データ分析 |
| 主たる目的 | 新たな仮説の「創出」(インサイトの獲得) | 既存の仮説の「検証」(客観的な証明) |
| 開始時の仮説 | 不要(データから探索的に見出す) | 必須(明確な仮説が定義されている) |
| 解析の自由度 | 極めて高い(試行錯誤的なデータ変換やサブグループ解析が可能) | 極めて低い(事前計画書に則り、逸脱のない解析が求められる) |
| 主要な解析手法 | 記述統計、データ可視化、主成分分析などの多変量解析 | 推測統計(各種パラメトリック/ノンパラメトリック検定、p値算出) |
| 結果の科学的解釈 | 「〇〇という傾向が示唆される(仮説段階)」 | 「〇〇であることが統計学的に実証された(証拠段階)」 |
| 信頼性担保の仕組み | 解析者の倫理観とオープンな探索プロセス | 公的試験登録、社内プロトコルの事前固定 |
| 臨床試験での位置づけ | パイロット試験、探索的試験、事後解析(Post-hoc 解析) | 検証的試験(第Ⅲ相試験、機能性届出の根拠となる臨床試験) |
探索的データ分析と仮説検証型データ分析を混同するリスク
特に発生しやすい不適切な運用が、「探索的解析によって事後的に見出した有意な差を、あたかも事前検証によって得られた主要な成果であるかのように発表・利用すること」です。統計学的には、これらは pハッキング や HARKing と呼ばれ、強く戒められています。
多重比較による「偽陽性」の拡大プロセス
有意水準を 5%(α = 0.05)に設定した場合、各検定で誤って有意差があると判定してしまう確率(第一種の過誤)は 5% です。しかし、事前に評価項目を特定せず、独立した検定を仮に20回繰り返した場合、「少なくとも1つの項目で偶然に有意差(p < 0.05)が生じる確率」は約 64% まで跳ね上がります。

何十通りものグループ分けを事後的に試行した結果、偶然得られた「p < 0.05」の項目(例:「睡眠6時間以上かつコーヒーを毎日飲む群で有意差あり」など)を取り出し、「本試験において効果が実証された」と主張することは、統計学的に誤りです。
統計学的な対処法:多重性の調整
どうしても1つのデータセットから複数の項目を探索・評価したい場合、統計学的に多重性を補正(有意水準を厳しく調整)する手法が用いられます。代表的な手法として以下が挙げられます。
- ボンフェローニ(Bonferroni)補正
- 最も単純かつ保守的な補正方法です。全体の有意水準 α を比較回数 m で割った値(α / m)を各検定の有意水準として用います。例えば20回検定を行う場合、基準となるp値は 0.05 / 20 = 0.0025 となり、偽陽性を極めて厳しく抑制します。
- ホルム(Holm)のステップダウン法
- ボンフェローニ補正よりも検出力(実際に差があるときに見落とさない確率)を高めた手法です。得られたp値を小さい順に並べ、順位に応じて有意水準を段階的に調整します。
- FDR(False Discovery Rate)制御(Benjamini-Hochberg法など)
- 有意と判定された結果の中に含まれる「偽陽性の割合」を一定値(例:5%)以下に抑えることを目指す手法です。ゲノム解析や大規模なスクリーニングなど、比較回数が非常に多い場合に有効です。
これらの手法を適用することは、探索的データ分析から仮説検証型データ分析へ移行する前段での仮説の確からしさを評価する際に有効なプロセスとなります。
構築すべき「研究開発の推進サイクル」
イノベーション創出(仮説発見)と科学的厳密性(エビデンス立証)を両立させるためには、探索的データ分析と仮説検証型データ分析を適切に連携させた以下の推進サイクルを回すことが重要です。
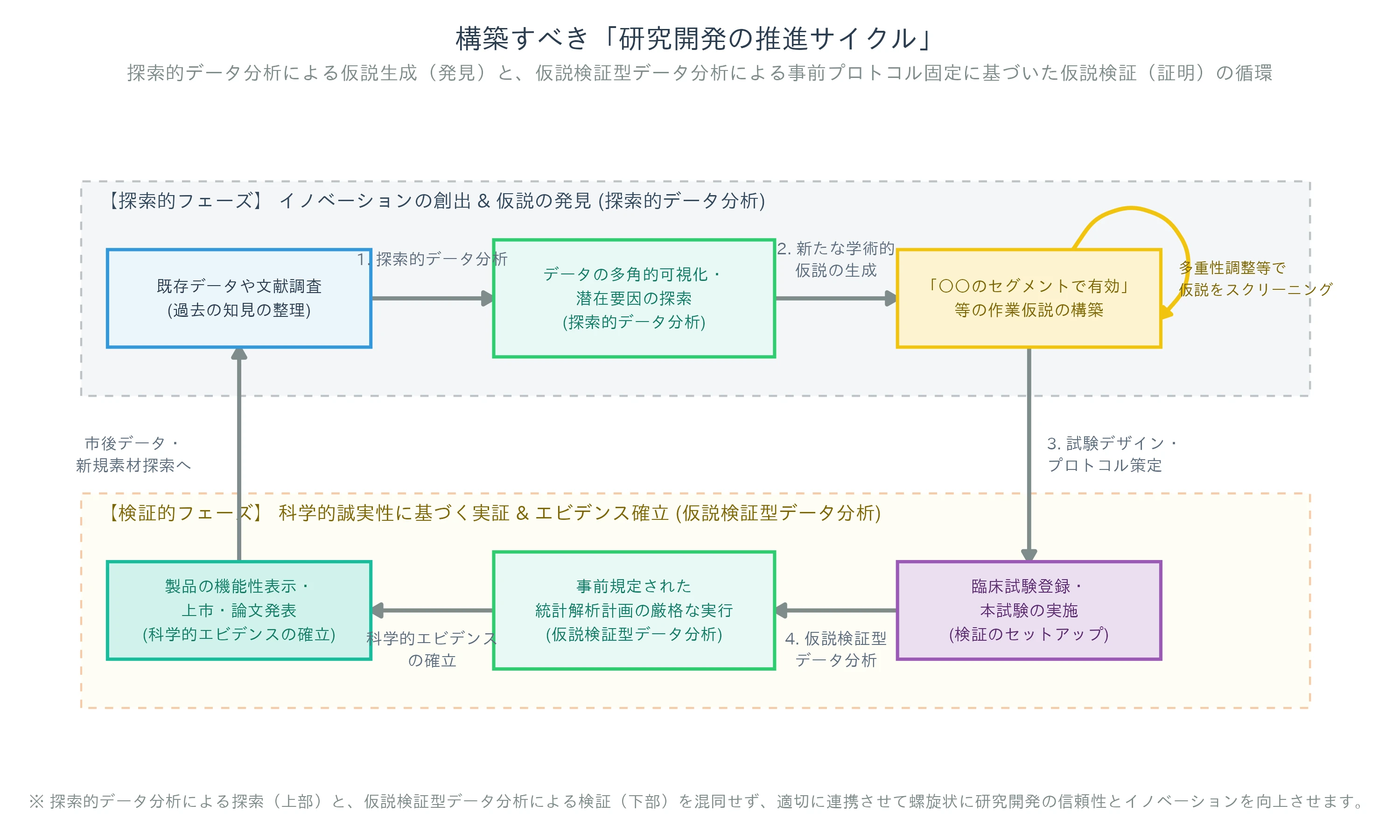
探索的データ分析による「仮説の探索と絞り込み」
過去の試験データ、パイロット試験(少数被験者による予備試験)、あるいは既存文献のデータを対象に、探索的データ分析を徹底的に行います。ここでは、多重性調整などの概念を用いて「偶然らしきシグナル」を排除しつつ、本当に再現性が高そうな有望な仮説を絞り込みます。
仮説検証型データ分析による「仮説の厳格な証明」
有望な仮説が定まった段階で、新規の本試験(検証的試験)を設計します。事前に「プロトコルの社内タイムスタンプ登録」や公的データベースへの登録を完了させ、試験終了後は一切のルールの逸脱なく仮説検証型データ分析を実行し、確固たるエビデンスを樹立します。
まとめ
探索的データ分析と仮説検証型データ分析は、研究開発における「車の両輪」です。
- 探索的データ分析は、固定観念にとらわれず、データの中からイノベーションの鍵となる「仮説を発見する」ためにあります。
- 仮説検証型データ分析は、事前定義されたルールに基づき、そのイノベーションが「真実であるかを証明する」ためにあります。
自社の試験データを扱う際には、現在実施しているデータ解析がどちらのフェーズに属しているかを明確にし、適切な統計手法と運用フローを用いて、科学的誠実性に基づいた研究開発を推進していきましょう。