
現代のR&Dが直面する「先鋭化」の罠
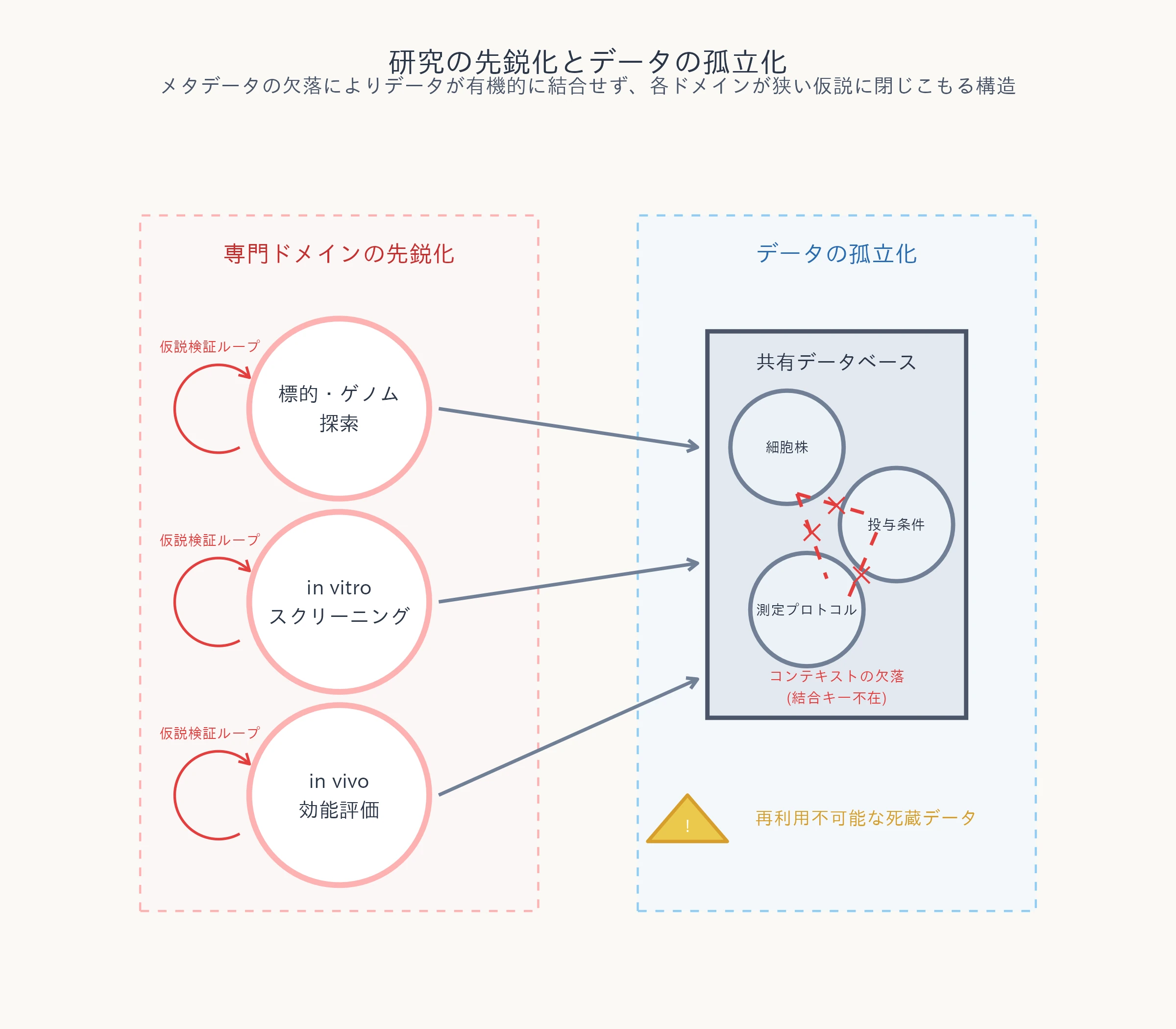
共通プラットフォームにおけるデータの死蔵と知のガラパゴス化
現代のライフサイエンスやマテリアルズインフォマティクスの現場では、実験の自動化やハイスループット計測の普及により、蓄積されるデータ量が指数関数的に増加しています。
しかし、多くのR&D組織で、これらのデータが資産として活用されているとは言い難い状況にあります。
実験データは社内の共有データベースやクラウドストレージに保存されていますが、実験がどのような意図や詳細な環境条件で行われたかという背景情報が欠落しているケースが多いためです。
結果として、データは以下のような課題に直面し、研究のボトルネックとなっています。
- 共有データベース内のデータについて、数値は追えるものの、詳細な実験条件が不明なため他者が再利用できない。
- 個々の研究者が自身の狭い専門領域と既知の仮説に閉じこもり、実験や分析が局所的に**先鋭化**(属人化およびガラパゴス化)している。
- 異なる実験バッチや他分野のデータと組み合わせた統合解析を行おうとしても、データの結合キーが存在せず、前処理だけで膨大な時間を浪費している。
ここでは、この「先鋭化」の罠を打破するために重要となる探索的データ分析のマインドセットと、それを組織的に支えるデータアーキテクチャ、特に実験メタデータの標準化について、具体的なユースケースを交えて解説します。
仮説検証型から探索的データ分析へのパラダイムシフト
イノベーションを創出するデータ主導の問い
従来のR&Dでは、仮説検証型データ分析が主流でした。
これは、「〇〇という薬液を添加すれば、効果が向上するはずだ」という明確な仮説をあらかじめ立て、それを検証するための実験を行い、統計的な有意差を検証する手法です。
確かに仮説検証は、既存の科学的知見を堅実に一歩進めるためには有効なアプローチです。
しかし、このアプローチだけに依存していると、研究者の「想定内」の範囲に収まる発見しか得られないという限界があります。
もし初期の仮説が誤っていたり、視野が狭かったりした場合、その実験データに含まれているかもしれない「未知の因子」や「想定外の相互作用」は見落とされてしまいます。
これに対して、探索的データ分析は、あらかじめ固定された仮説を持たずに、データを様々な角度から可視化や要約を行い、データそのものが語るパターンや異常値、関係性を探索するアプローチです。
米国の数学者・統計学者ジョン・ワイルダー・テューキーは著書「Exploratory Data Analysis」で、「探索的データ分析とは、データの中にある発見を求める探偵の仕事である」と述べています。
異なる変数同士の関係性をプロットし、外れ値の背後にある物理的あるいは生物学的な背景を考察することで、次世代の研究テーマとなる新たな仮説(イノベーションの種)が生まれます。
仮説検証型データ分析が仮説を「検証」するためのものであるならば、探索的データ分析はより良い仮説を「生成」するためのエンジンなのです。
| 比較項目 | 仮説検証型データ分析 | 探索的データ分析 |
|---|---|---|
| 主たる目的 | 設定した仮説の妥当性を統計的に検証・確定する | データから隠れたパターンや新たな仮説を発見する |
| 開始時の仮説 | 必須(明確な帰無仮説と対立仮説を定義) | 不要(あるいは非常に緩やかな問いから開始) |
| 解析の自由度 | 低い(事前に定義した解析計画書を厳格に遵守) | 極めて高い(可視化や変数の組み合わせを自在に変更) |
| 主要なツール・手法 | 仮説検定(t検定、ANOVA)、信頼区間、回帰分析 | 散布図行列、箱ひげ図、主成分分析、クラスタリング |
| 発生しやすい過誤 | 第II種の誤り(真の効果を見落とすリスク) | 第I種の誤り(偶然のパターンを真の発見と誤認するリスク) |
| 信頼性担保の仕組み | 解析計画の固定、事前登録、有意水準の厳格な管理 | 独立した別データセットを用いた仮説検証型データ分析による事後検証 |
探索する前に抑えておきたい点
探索的データ分析を実行する上で大前提となるのは、探索的データ分析はあくまでも仮説をつくる(仮説生成)ための分析であり、その仮説の検証(仮説検証)には必ず独立した別のデータセットを使用する、という原則です。
この原則を怠り、同一のデータセットで仮説の発見と検証を同時に行おうとすると、再現性のない偽陽性を真の発見と誤認する統計的な罠に陥ります。
この統計的な罠の代表例として、pハッキングとHARKingの2つをお伝えします。
意図しないデータの選択的利用であるpハッキング
pハッキングとは、解析者が有意な結果(通常は p < 0.05)を得るために、データの前処理や解析手法を事後的に選択・調整する行為です。 これには、以下のような操作が含まれます。
- 有意差が出るまで外れ値を恣意的に除外する
- 解析結果を見ながら特定の変数やセグメントのみを選択して検定する
- 有意差が出た時点でデータの収集や追加を停止する
- 異なる統計検定を次々と試して有意になったものだけを採用する
この問題は、探索と検証を同一のデータで行い、そのデータに対して高い解析の自由度を適用し続けることで発生します。
探索段階で算出されるp値は、単に「興味深い関係性」を示す探索のガイドラインにすぎず、統計的な検証力はないことを覚えておく必要があります。
結果に伴う後付けの仮説構築であるHARKing
HARKing(Hypothesizing After the Results are Known)とは、データを分析して得られた結果を見てから仮説を構築し、それをあたかも実験開始前から存在していた仮説であるかのように報告する行為です。
これも、探索によって「見つかってしまった」偶然のノイズに対する後付けの説明を、別のデータでの検証を通さずに「正しい仮説」として確定しようとする姿勢から生じます。
結果を見た後に構築された仮説の再現性は保証されないことを覚えておく必要があります。
領域の壁を越える統合解析の例(血液成分と睡眠データの結合)
専門性の殻を破り日常生活のコンテキストを接続する
ここで、ヒトを対象としたヘルスケアやライフサイエンスの領域における具体的なユースケースを考えてみましょう。
ある研究所の研究者Aは、血液中の特定の代謝物(メタボライト)の挙動を専門に研究しています。
研究者Aは、生活習慣病リスクの低減に向けて、脂質成分の血中濃度の変動を長年追っていますが、従来の臨床試験データだけでは個人差が大きく、明確な介入効果を見出せずに悩んでいました。
ある日、データサイエンティストの提案により、被験者のスマートウォッチから得られた「睡眠データ(総睡眠時間、深い睡眠(ノンレム睡眠)の割合、中途覚醒回数など)」という、血液学とは全く異なるドメインのデータを統合することになりました。
研究者Aは当初、「睡眠時間と血液中の局所的な代謝物に、直接的な関係などあるはずがない」と懐疑的でした。
研究者Aが探索的データ分析を実践した具体的なプロセスは、以下のステップに分解されます。
- 単変量の分布確認(外れ値の検出):まず、脂質成分や睡眠データの各項目のヒストグラムを描き、測定ミスや異常値(デバイスの未装着など)がないかをスクリーニングしました。
- 2変数間の相関確認:次に、脂質成分の濃度と総睡眠時間、ノンレム睡眠の割合といった変数ペアの相関係数を算出し、散布図行列(ペアプロット)を作成して全体を俯瞰しました。
- 多次元可視化・グループ化による文脈の抽出:全体を俯瞰した結果から「ノンレム睡眠の割合」に焦点を絞り、被験者の年齢や性別といった背景属性をカラーマッピングした3次元的なプロットを作成して、特定の条件下でのみ相関が現れるスイッチング現象を発見しました。
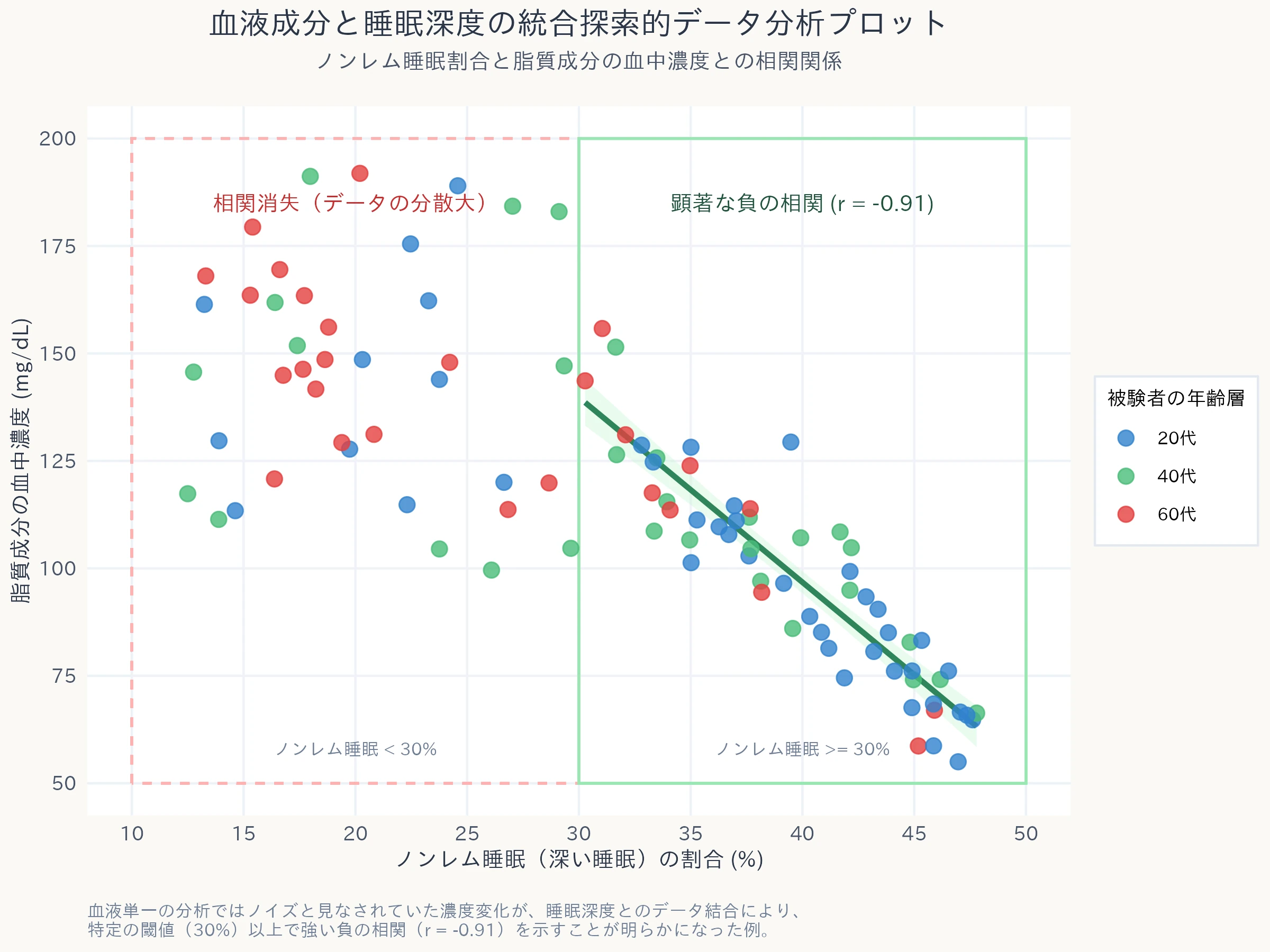
このステップで結合されたデータに対して探索的データ分析を試みたところ、これまでの常識を覆すパターンが視覚的に浮かび上がりました。
単に脂質成分の濃度と介入条件だけでプロットしていたときには、単なる「ばらつき(ノイズ)」として処理されていたデータが、横軸に「ノンレム睡眠の割合」、縦軸に「脂質成分の濃度」をとった散布図を描いた瞬間、特徴が浮かび上がってきたのです。
ノンレム睡眠の割合が全体の30%を超える良好な睡眠をとっている被験者グループにおいてのみ、脂質成分の濃度と睡眠の深さに強い負の相関(相関係数 = -0.91)が存在することが確認されました。
この発見は、血液成分という閉じたドメインの解析だけでは到達できなかった知見です。
被験者の日常生活というコンテキスト(文脈情報)を結合し、探索的データ分析によってデータを可視化したからこそ、「深い睡眠が特定の脂質代謝経路の活性化を促しているのではないか」という、新たな生理学的仮説が生成されたのです。
研究者Aは現在、この探索的データ分析で得られた仮説を検証するため、睡眠介入プログラムを組み合わせた新しい臨床試験の設計を進めています。
探索を支えるデータアーキテクチャと実験メタデータの標準化
数値の羅列を有機的な知識ネットワークへ変革する
前述のような血液データと睡眠データの統合解析は、ストーリーとして聞く分には魅力的ですが、実際のR&D現場で実行しようとすると、高い技術的および運用上の障壁に直面します。
血液データは特定の臨床試験管理システムから出力されたCSVファイルであり、睡眠データはウェアラブルデバイスのベンダーが提供する独自フォーマットのJSONデータだからです。
これらを統合するためには、最低限、被験者を一意に識別する共通のIDや、実験の日時情報(タイムスタンプ)が厳格に一致していなければなりません。
PythonやRのプログラミングスキルを持つ研究者であっても、元データのフォーマットが不統一で、必要な実験条件が記載されていなければ、データの前処理(データクレンジング)だけで業務時間の8割を費やすことになります。
これでは、自由な探索など到底不可能です。
探索的データ分析を組織の持続的な武器とするためには、強固なデータアーキテクチャの確立と、実験の背景情報を定義する実験メタデータの標準化が必要です。
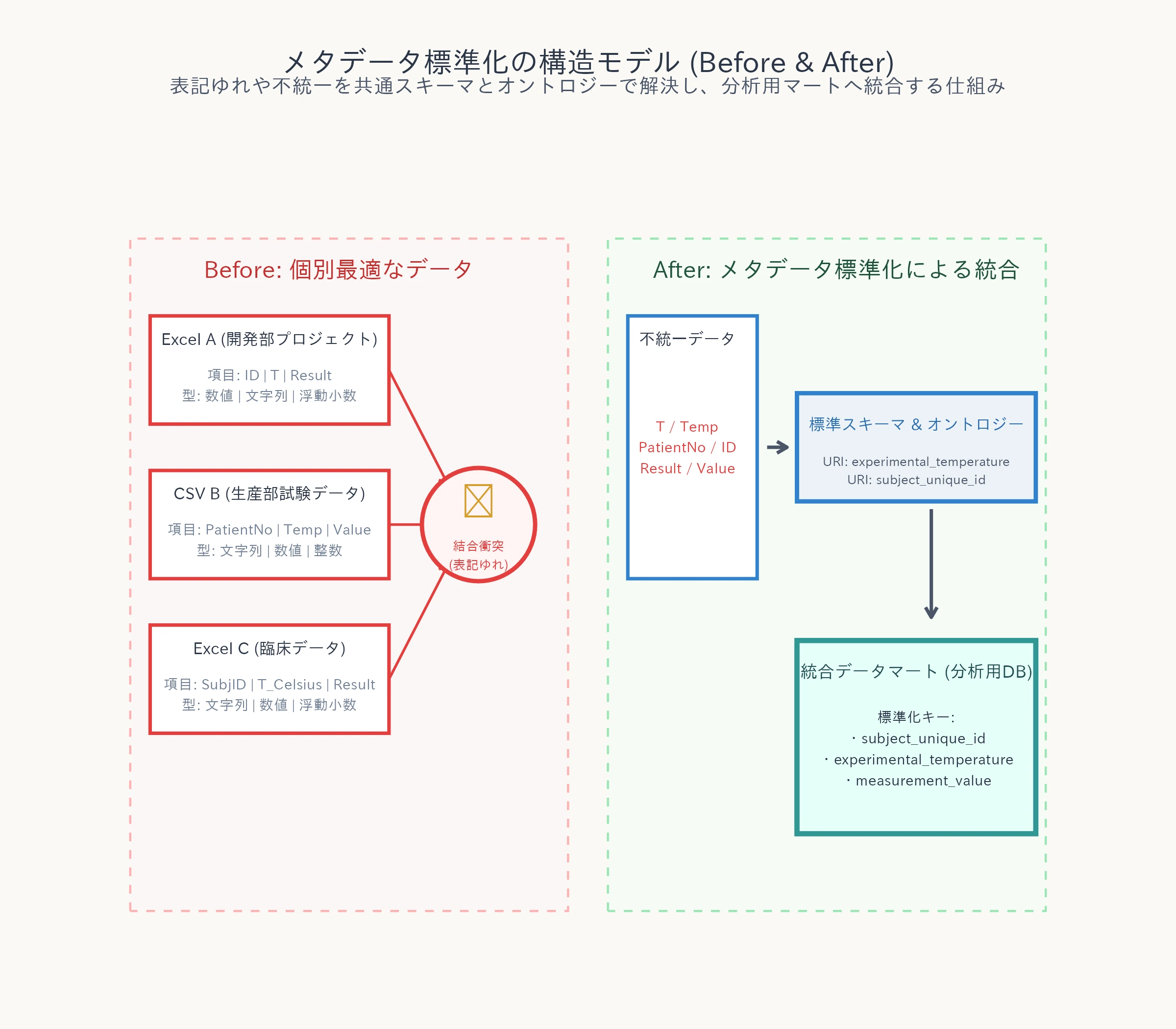
実験における生データ(数値)に対し、実験メタデータは実験の背景条件や測定環境などのコンテキスト(文脈情報)を付与する役割を果たします。実験メタデータが欠落したデータベースは、文脈を失った数値の羅列にすぎず、そこから意味のある知見を読み取ることはできません。
実験メタデータの標準化においては、単に記述フォーマットを揃えるだけでなく、業界標準のオントロジー(知識の体系的表現)やデータスキーマの導入が必要です。
例えば、温度の項目名について、あるプロジェクトでは「Temp」、別の実験では「Temperature」、さらには「T_Celsius」と不統一に命名されていた場合、機械的な自動統合は不可能です。
これを「experimental_temperature」という統一されたURI(Uniform Resource Identifier)に関連付けられた共通のオントロジーとして定義することで、システムは自動的にこれらが同一の物理量であることを理解できます。
例えば、実験の文脈を機械可読にするための実験メタデータのスキーマ定義(YAML形式)の具体例を以下に示します。
metadata_schema:
schema_version: "1.0.0"
standard_ontology: "ISA-Tab / OBI"
experiment_context:
project_code:
type: "string"
pattern: "^PRJ-[0-9]{4}$"
description: "組織で統一されたプロジェクトコード"
experimenter_id:
type: "string"
description: "実験実施者の一意なID"
environmental_factors:
experimental_temperature:
type: "number"
unit: "Celsius"
required: true
description: "インキュベーターの設定温度"
humidity_percent:
type: "number"
unit: "percent"
range: [0, 100]
sample_attributes:
subject_unique_id:
type: "string"
required: true
description: "被験者またはサンプルロットの一意なID"
preparation_protocol_uri:
type: "string"
format: "uri"
description: "電子実験ノートのプロトコルURL"
このようなデータスキーマをあらかじめ規定し、共通のオントロジーを適用しておくことで、データの収集と統合プログラミングのコストは大きく削減されます。
標準化されたデータを維持するデータパイプライン
組織的に実験メタデータの標準化を維持し、研究者の負担を増やさずに高品質なデータを蓄積するためには、実験プロトコルの策定からデータ解析にいたる循環型のライフサイクルをシステム化する必要があります。
以下に、R&D部門におけるデータアノテーションと運用のサイクルを示します。
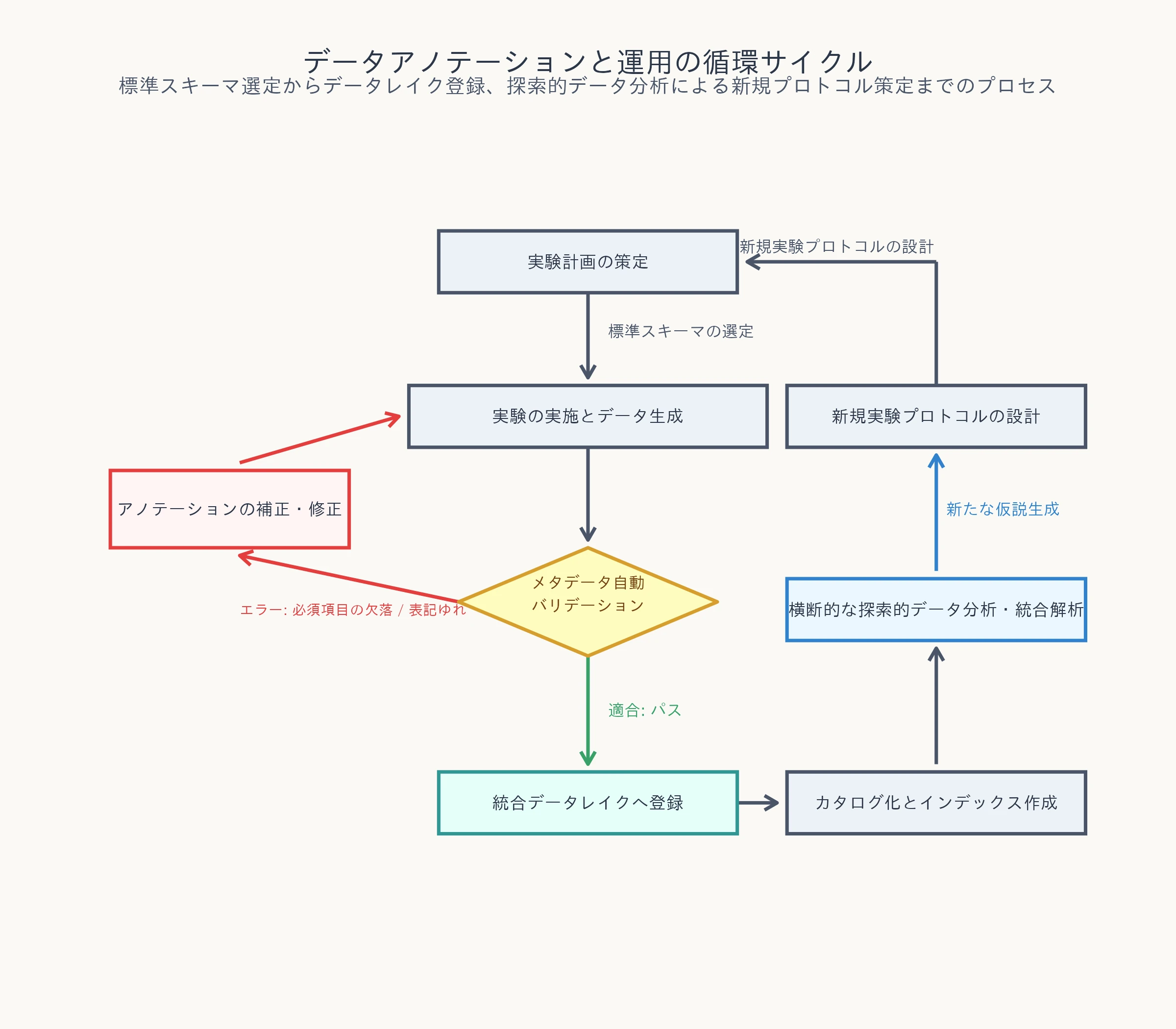
このサイクルが示すように、実験の計画段階であらかじめ共通のデータスキーマを規定しておくことで、データ生成時のバリデーション(検証)を自動化できます。
エラーとなったデータは登録を却下し、その場で修正を促す仕組み(ゲートキーパー)を設けることで、データレイクがデータ沼(データのゴミ捨て場)化することを防ぎます。
こうしてクリーンに保たれた統合データレイクこそが、ドメインを超えた探索的データ分析を何度でも即座に実行できる肥沃な土壌となるのです。
データが対話する未来のR&Dに向けて
研究者の直感とデータアーキテクチャの共鳴
R&D部門の研究者が持つ、特定ドメインに対する深い洞察力と専門知識は、他者には決して真似できない最大の武器です。
しかし、その強い専門性ゆえに、自ら設定した仮説の枠組みに縛られ、データが秘めている別の可能性を見落とししてしまうことは、科学の歴史において珍しくありません。
探索的データ分析は、研究者を仮説の呪縛から解放し、データとの自由な対話を可能にするマインドセットです。
そして、その自由な対話を技術的に支え、異なる領域の知見を有機的に結びつけるのが、データアーキテクチャと実験メタデータの標準化というインフラです。
データが部署や専門性の壁を越えて互いに対話を始めるとき、研究者の直感はこれまでにない解像度で研ぎ澄まされます。
まずは、日々の実験記録における「1つの変数の命名規則の統一」や「温度単位の統一」といった、小さな標準化から始めてみませんか。
その地道な一歩こそが、組織全体の知を繋ぎ、明日の破壊的なブレイクスルーをもたらす強固な礎となるはずです。