
統計的検定の流れ
検定の大まかな流れを確認しておきます。
- 帰無仮説H0と対立仮設H1をたてます
- 有意水準を決めて、棄却域を決定します
- 検定統計量を計算します
- 検定統計量が棄却域にあれば帰無仮説H0を棄却し、対立仮設H1を採択します。そうでなければ、帰無仮説H0を採択します
母平均と標本平均が異なることを検定したい場合
母平均を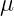

母平均が標本平均と異なることを検定したい場合は、両側検定として次のような仮説をたてます。
- 帰無仮説
- 対立仮説


母平均が標本平均より大きいことを検定したい場合
母平均を
母平均が標本平均より大きいことを検定したい場合は、片側検定として次のような仮説をたてます。
- 帰無仮説
- 対立仮説

母平均が標本平均より小さいことを検定したい場合
母平均を
母平均が標本平均より小さいことを検定したい場合は、片側検定として次のような仮説をたてます。
- 帰無仮説
- 対立仮説

理論
母分散が未知の場合の母平均の検定の理論的枠組みを解説します。
標本xの標本平均を


分散の推定値
また、有意水準を
検定統計量
母平均の検定における検定統計量
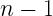

信頼区間
信頼区間は次のように表すことができます。

これを変形すると次のようになります。

よって、信頼係数$1-\alpha$の信頼区間は次のようになります。
![[\overline{x}-t_{\frac{\alpha}{2}}\frac{\hat{\sigma}}{\sqrt{n}}, \overline{x}+t_{\frac{\alpha}{2}}\frac{\hat{\sigma}}{\sqrt{n}}]](https://s0.wp.com/latex.php?latex=%5B%5Coverline%7Bx%7D-t_%7B%5Cfrac%7B%5Calpha%7D%7B2%7D%7D%5Cfrac%7B%5Chat%7B%5Csigma%7D%7D%7B%5Csqrt%7Bn%7D%7D%2C+%5Coverline%7Bx%7D%2Bt_%7B%5Cfrac%7B%5Calpha%7D%7B2%7D%7D%5Cfrac%7B%5Chat%7B%5Csigma%7D%7D%7B%5Csqrt%7Bn%7D%7D%5D+&bg=ffffff&fg=000&s=4&c=20201002)
R実装
Rで母分散が未知の場合の母平均の検定を行う場合は、基本パッケージstatsに実装されているt.test関数を用います。
getAnywhere関数の引数にt.test.defualtを渡すと
getAnywhere(t.test.default)
t.test.defualt関数の実装を見ることができます。
A single object matching ‘t.test.default’ was found
It was found in the following places
registered S3 method for t.test from namespace stats
namespace:stats
with value
function (x, y = NULL, alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, var.equal = FALSE, conf.level = 0.95,
...)
{
alternative <- match.arg(alternative)
if (!missing(mu) && (length(mu) != 1 || is.na(mu)))
stop("'mu' must be a single number")
if (!missing(conf.level) && (length(conf.level) != 1 || !is.finite(conf.level) ||
conf.level < 0 || conf.level > 1))
stop("'conf.level' must be a single number between 0 and 1")
if (!is.null(y)) {
dname <- paste(deparse(substitute(x)), "and", deparse(substitute(y)))
if (paired)
xok <- yok <- complete.cases(x, y)
else {
yok <- !is.na(y)
xok <- !is.na(x)
}
y <- y[yok]
}
else {
dname <- deparse(substitute(x))
if (paired)
stop("'y' is missing for paired test")
xok <- !is.na(x)
yok <- NULL
}
x <- x[xok]
if (paired) {
x <- x - y
y <- NULL
}
nx <- length(x)
mx <- mean(x)
vx <- var(x)
if (is.null(y)) {
if (nx < 2)
stop("not enough 'x' observations")
df <- nx - 1
stderr <- sqrt(vx/nx)
if (stderr < 10 * .Machine$double.eps * abs(mx))
stop("data are essentially constant")
tstat <- (mx - mu)/stderr
method <- if (paired)
"Paired t-test"
else "One Sample t-test"
estimate <- setNames(mx, if (paired)
"mean of the differences"
else "mean of x")
}
else {
ny <- length(y)
if (nx < 1 || (!var.equal && nx < 2))
stop("not enough 'x' observations")
if (ny < 1 || (!var.equal && ny < 2))
stop("not enough 'y' observations")
if (var.equal && nx + ny < 3)
stop("not enough observations")
my <- mean(y)
vy <- var(y)
method <- paste(if (!var.equal)
"Welch", "Two Sample t-test")
estimate <- c(mx, my)
names(estimate) <- c("mean of x", "mean of y")
if (var.equal) {
df <- nx + ny - 2
v <- 0
if (nx > 1)
v <- v + (nx - 1) * vx
if (ny > 1)
v <- v + (ny - 1) * vy
v <- v/df
stderr <- sqrt(v * (1/nx + 1/ny))
}
else {
stderrx <- sqrt(vx/nx)
stderry <- sqrt(vy/ny)
stderr <- sqrt(stderrx^2 + stderry^2)
df <- stderr^4/(stderrx^4/(nx - 1) + stderry^4/(ny -
1))
}
if (stderr < 10 * .Machine$double.eps * max(abs(mx),
abs(my)))
stop("data are essentially constant")
tstat <- (mx - my - mu)/stderr
}
if (alternative == "less") {
pval <- pt(tstat, df)
cint <- c(-Inf, tstat + qt(conf.level, df))
}
else if (alternative == "greater") {
pval <- pt(tstat, df, lower.tail = FALSE)
cint <- c(tstat - qt(conf.level, df), Inf)
}
else {
pval <- 2 * pt(-abs(tstat), df)
alpha <- 1 - conf.level
cint <- qt(1 - alpha/2, df)
cint <- tstat + c(-cint, cint)
}
cint <- mu + cint * stderr
names(tstat) <- "t"
names(df) <- "df"
names(mu) <- if (paired || !is.null(y))
"difference in means"
else "mean"
attr(cint, "conf.level") <- conf.level
rval <- list(statistic = tstat, parameter = df, p.value = pval,
conf.int = cint, estimate = estimate, null.value = mu,
alternative = alternative, method = method, data.name = dname)
class(rval) <- "htest"
return(rval)
}
<bytecode: 0x69251f8>
<environment: namespace:stats>
検定統計量
母平均の検定における検定統計量に関するR実装のうち、本質的な箇所を抜き出すと以下のようになります。
nx <- length(x) # 標本の大きさ
mx <- mean(x) # 標本平均
vx <- var(x) # 分散の推定値(不偏分散)
if (is.null(y)) {
df <- nx - 1 # 自由度
stderr <- sqrt(vx/nx) # 検定統計量の右辺の分母
tstat <- (mx - mu)/stderr # 検定統計量
}
p値と信頼区間
p値と信頼区間に関するR実装のうち、本質的な箇所を抜き出すと以下のようになります。
pt(t0, df)関数は、自由度dfのt分布における統計量t0に対する下側確率P(t < t0)を計算します。
qt(p, df)関数は、自由度dfのt分布における確率pに対する統計量t0を計算します。
if (alternative == "less") {
pval <- pt(tstat, df) # 対立仮説x<mu: p値
cint <- c(-Inf, tstat + qt(conf.level, df)) # 対立仮説x<mu: 信頼係数conf.levelの限界値
}
else if (alternative == "greater") {
pval <- pt(tstat, df, lower.tail = FALSE) # 対立仮説x>mu: p値, lower.tail=FALSEで上側確率を計算
cint <- c(tstat - qt(conf.level, df), Inf) # 対立仮説x>mu: 信頼係数conf.levelの限界値
}
else {
pval <- 2 * pt(-abs(tstat), df) # 対立仮説x!=mu: p値, 両側検定なので下側確率の2倍を計算
alpha <- 1 - conf.level # 有意水準
cint <- qt(1 - alpha/2, df) # 両側検定なので、1から有意水準の1/2を引いた確率に対する統計量を計算
cint <- tstat + c(-cint, cint) # 対立仮説x!=mu: 信頼係数conf.levelの限界値
}
cint <- mu + cint * stderr # 信頼区間
例
あるクラスの身長を計測したところ、次のようになりました。
身長の分布が正規分布をすると仮定すると、このクラスの平均身長は全国平均170より大きいかを検定してみます。
ただし、有意水準5%とします。
データ:166, 168, 168, 169, 170, 171, 172, 173, 174, 175
t.test(c(166, 168, 168, 169, 170, 171, 172, 173, 174, 175),
alternative = "greater", mu = 170, conf.level = 0.95)
One Sample t-test
data: c(166, 168, 168, 169, 170, 171, 172, 173, 174, 175)
t = 0.65122, df = 9, p-value = 0.2656
alternative hypothesis: true mean is greater than 170
95 percent confidence interval:
168.9111 Inf
sample estimates:
mean of x
170.6
p値0.2656 > 有意水準0.05なので、棄却できません。
よって、このクラスの身長は全国平均よりも大きいとは言えません。